
The concept of Merkle tree was patented by Ralph Merkle in 1979, hence the name.
Merkle tree is a binary tree data structure where each leaf node stores the hash value of a data block, and non-leaf nodes store the hash of their two child node values (concatenating the two hash values and then hashing). Hash trees can efficiently and securely verify the content of large data structures.
Scenario
Suppose there are 1000 data blocks, each 1MB, and you need hash values (checksums) to ensure each data block hasn’t been modified during transmission. There are two approaches:
- During transmission, add 1000 hash values, one for each data block. The data receiver can use hash values to verify each block individually for modifications.
- Combine these 1000 blocks into one 1GB data block, then hash this 1GB block once. The data receiver can use the hash value to verify all 1000 blocks at once.
Both approaches have drawbacks:
- Approach 1: Increases the amount of data transmitted. Using SHA256, Approach 1 needs to add 999 hash values of 32 bytes each.
- Approach 2: Only needs to add a 32-byte checksum (hash value), which is efficient. But the problem is when the data receiver wants to check just one data block, they must get all 1000 data blocks, combine them, and calculate together to verify.
Merkle Tree provides a third approach.
Solution
Merkle Tree hashes each data block separately (similar to Approach 1 above), but doesn’t directly transmit this bunch of hash values. Instead, it concatenates pairs of hash values and hashes them again. Similar to World Cup matches, until finally getting one hash value, called the Merkle Root. Then transmit all data blocks together with the Merkle Root value.
The receiver gets all data blocks and the Merkle Root value. Using the algorithm above, they can recalculate to verify if the Merkle Root matches the value from Merkle hashing the data blocks.
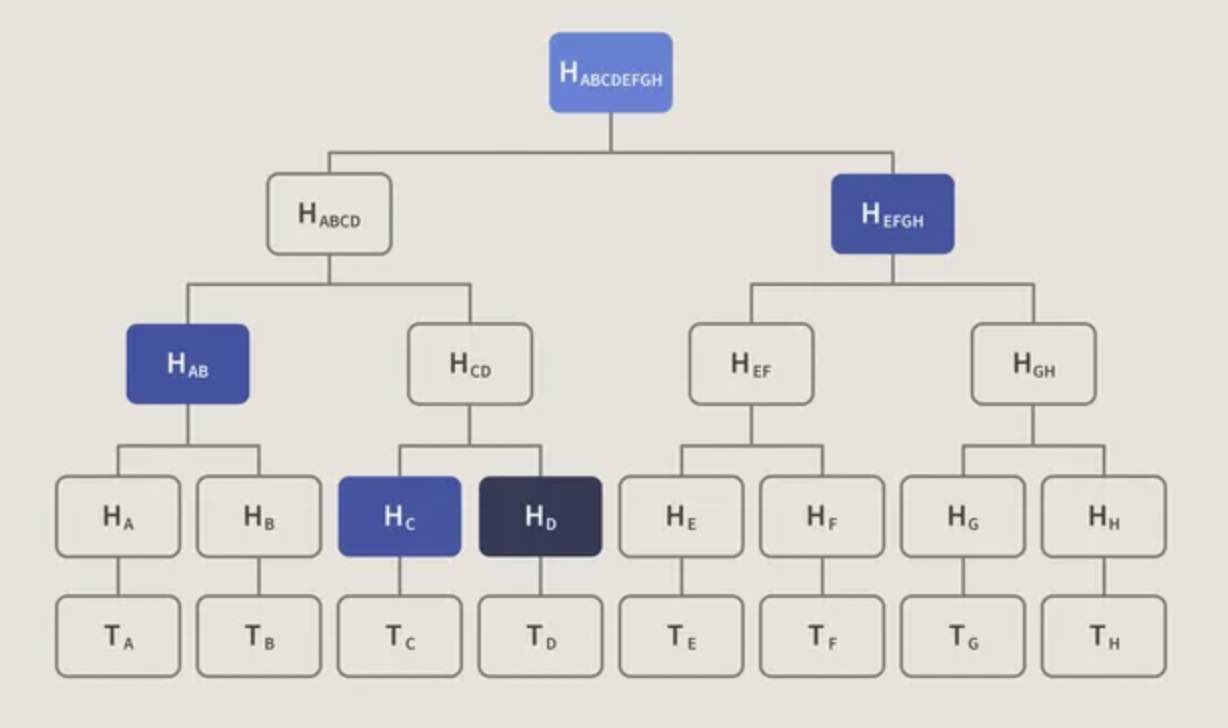
If the receiver only wants to verify one data block’s integrity. For example, in the Bitcoin case shown above, if the receiver only wants to know if transaction T(D) is in the current block, they only need to get four hash values: H(C), H(AB), H(EFGH), and the Merkle Root to verify. When there are more data blocks, Merkle Tree has more levels. To verify one data block, you need the hash values of all sibling nodes on the branch from the root to the leaf node containing that block. Hash values are generally only 32 bytes, much shorter than transaction blocks.
In Bitcoin, SPV nodes use this property of Merkle Tree to optimize interaction with trusted nodes, greatly reducing data transmission.
Why don’t SPV nodes directly ask a trusted node for the H(D) value for verification? Because H(D) could be forged. But the Merkle Root value is saved in the current block’s header on the blockchain, which has integrity protection. Verifying by comparing with the Merkle Root is more reliable. Due to the one-way nature of hash functions, malicious nodes cannot forge hash values on the branch from the Merkle Root - technically impossible (would need to solve hash collision problems).
Use Cases
Merkle Tree is used in distributed systems for efficient data verification. It has been widely adopted in the industry. Here are some examples:
- Version control tool - Git
- P2P browser - Tor
- Blockchain related: Bitcoin, Ethereum, Filecoin, etc.